Authors: Ye Yuan, Zhidong Guo
We are going to implement two variants of in-memory parallel hash join to examine the effect of CPU cache hit rate, synchronization cost, and computation cost on performance.
https://github.com/cmu-15618-team/parallel-hash-join/blob/main/report/project-proposal.md
Join operation is arguably the most important operation in relational DBMS. It offers the ability to combine two or more relations (tables) together so that the users can organize their data in multiple relations which more accurately reflects the data model in reality, eliminates duplicated data, ensures consistency, and so forth. It is also one of the most crucial operations in terms of performance because join appears in virtually every SQL query, and a bad implementation of join can be devastatingly slow. Among various join algorithms, hash join has been one of the most well-studied and widely-adopted algorithms due to its conceptual simplicity and its linear time complexity with respect to the number of pages in both relations (in a disk-oriented context).
For readers not coming from a database system world, a hash join typically works in two phase: the build phase and the probe phase. In the build phase, a hash function is applied to the join key of every tuple in the left (inner) table, mapping them into hash buckets based on the hash values. In the probe phase, the algorithm iterates through the right (outer) table, applying the same hash function to its tuples. It uses the hash value to locate the hash bucket storing tuples from the left table with the same hash value, and hence potentially the same join key. For every matching tuple from both relations, an output tuple is produced. These two stages are illustrated in the below figure.
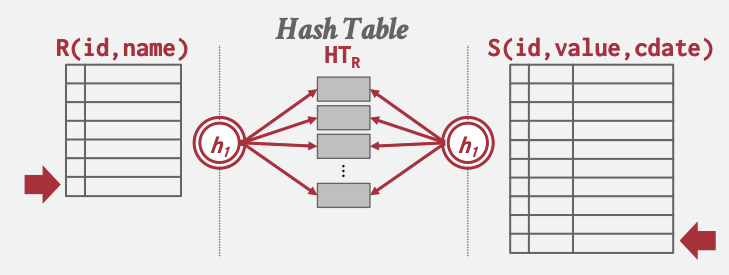
The first challenge is implementing hash joins efficiently. More specifically,
The second challenge is designing the workload that reasonably reflects real-world workload and can simulate different data skewness.
For now, we plan to use GHC machines to do the evaluation. In terms of software, we plan to build the system from scratch using Rust, as modifying existing systems would require too much work that is irrelevant to our topic. We will refer to this paper for implementation and evaluation guidelines.
The final program should be an efficient implementation of hash join that is supposed to be much faster than sequential implementation.
Time permitting, we will implement other variants of hash join, such as independent-partitioned hash join, and radix hash join.
We choose GHC cluster because it has 16GB of memory and 12 MB of L3 cache, which should be large enough for our testing purposes.
| End Date | Task |
|---|---|
| 4-8 | Implement infrastructure such as input/output, hash table, partition buffer, and sequential hash join |
| 4-16 | Implement the first variant of hash join |
| 4-24 | Implement the second variant of hash join |
| 4-30 | Design workload and perform evaluations |
| 5-5 | Report writing |